
Un rapport récent relance l’idée d’un virage majeur chez OpenAI : l’avenir de ChatGPT ne se jouerait plus seulement sur l’écran, mais aussi dans l’oreille. Alors que l’assistant conversationnel s’est imposé par le texte, les fuites évoquent une génération de modèles orientés audio, conçus pour parler avec plus de naturel, mieux gérer les interruptions et, surtout, dialoguer en même temps que l’utilisateur. Autrement dit, l’expérience se rapprocherait d’une conversation humaine, avec ses hésitations, ses relances et ses chevauchements de parole.
Ce mouvement ne serait pas isolé. Il préparerait un premier appareil grand public signé OpenAI, pensé comme un objet personnel et discret, largement centré sur le son. Dans les scénarios discutés, des lunettes connectées et un haut-parleur intelligent sans écran reviennent souvent. En toile de fond, une question très concrète apparaît : une technologie « tout audio » peut-elle séduire un public habitué au texte, notamment dans les lieux partagés ? Pourtant, si le traitement vocal progresse au point de rendre la voix fiable, rapide et expressive, la donne change pour l’intelligence artificielle au quotidien.
- OpenAI préparerait de nouveaux modèles audio pour ChatGPT avant un appareil dédié.
- Le rapport évoque une voix plus naturelle, plus émotionnelle et plus précise dans les réponses.
- La capacité à parler en même temps que l’utilisateur et à gérer les interruptions serait un pivot.
- Un écosystème d’objets audio est cité, dont des lunettes et un haut-parleur sans écran.
- Les enjeux clés touchent la reconnaissance vocale, la latence, la confidentialité et l’adoption sociale.
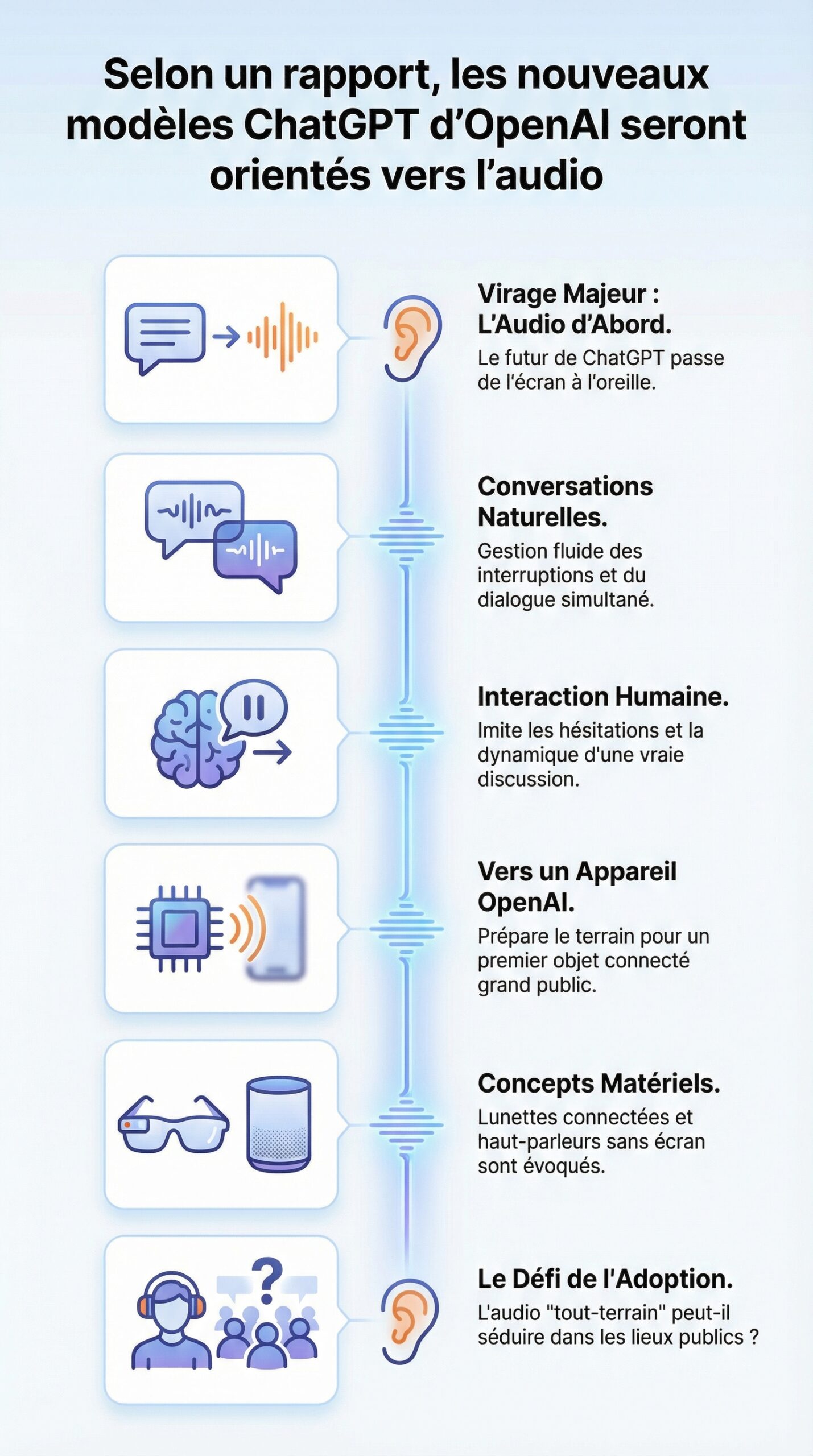
Un rapport sur OpenAI qui annonce des modèles ChatGPT orientés audio
Le rapport attribué à des sources proches du dossier décrit une préparation active de OpenAI autour de modèles vocaux renforcés. L’objectif est clair : rendre l’échange oral plus fluide, tout en améliorant la profondeur des réponses. Ainsi, le chantier ne porte pas seulement sur la synthèse vocale, mais aussi sur l’architecture qui relie compréhension, raisonnement et restitution audio.
Pour le grand public, le détail le plus parlant concerne la gestion des tours de parole. Aujourd’hui, beaucoup d’assistants imposent un schéma rigide : parler, attendre, écouter la réponse. Or, le document évoque une capacité nouvelle : ChatGPT pourrait parler pendant que l’utilisateur parle, puis s’ajuster en direct. Cette fonctionnalité change tout, car elle autorise l’interruption naturelle, comme dans une discussion réelle.
Des réponses plus naturelles grâce à une architecture audio repensée
Le texte insiste sur un rendu vocal plus expressif, avec un ton perçu comme plus « humain ». Cependant, l’intérêt technique dépasse l’émotion. Une voix naturelle aide aussi la compréhension, car l’intonation signale les priorités, les avertissements ou les nuances. Par conséquent, le traitement vocal devient une couche d’interface, mais aussi un outil d’ergonomie.
Un exemple concret illustre l’enjeu. Dans un service client, une réponse monotone peut être exacte, mais elle reste fatigante à écouter. À l’inverse, une prosodie maîtrisée indique les étapes, marque les points importants et réduit les répétitions. En pratique, cela diminue le temps d’appel, donc les coûts opérationnels.
Gestion des interruptions et reconnaissance vocale : la vraie bataille
La promesse la plus structurante concerne la robustesse face aux interruptions. Dans une cuisine, une voiture ou un open space, la voix est souvent coupée par des bruits et des phrases incomplètes. Or, la reconnaissance vocale doit distinguer une interruption volontaire d’un bruit parasite, puis décider si la réponse doit s’arrêter, se corriger ou continuer.
Imaginons une PME fictive, Atelier Dumas, qui équipe ses techniciens de casques audio sur chantier. Un technicien dicte : « donne-moi le couple de serrage pour la bride… », puis il se corrige : « non, pour la bride inox 316 ». Si le système gère mal l’interruption, il répond à côté. À l’inverse, un modèle entraîné pour ces cas d’usage réoriente la requête et cite la bonne norme. Au final, la qualité perçue dépend moins du “blabla” que de ces micro-ajustements.
Cette montée en gamme de l’audio prépare logiquement le matériel, car un assistant vocal fiable devient enfin « portable » dans la vie réelle. L’étape suivante concerne donc l’objet qui portera cette interaction.
Un appareil OpenAI axé audio : opportunité produit ou pari risqué ?
Selon les informations relayées, le premier appareil grand public de OpenAI serait largement orienté vers l’audio. L’idée n’est pas un simple gadget, mais un point d’entrée vers un écosystème. Toutefois, ce choix crée un risque évident : beaucoup d’utilisateurs préfèrent le texte, notamment en présence d’autres personnes.
Pourtant, l’audio a un avantage décisif : il libère les mains et les yeux. Ainsi, une interaction vocale peut s’imposer dans les moments où l’écran est impraticable. On pense à la cuisine, au bricolage, à la conduite ou aux interventions terrain. De plus, un objet audio discret réduit la friction : pas besoin d’ouvrir une application ni de se connecter à un poste de travail.
Pourquoi un écosystème d’objets sans écran revient à la mode
Le rapport mentionne des concepts comme des lunettes et un haut-parleur sans affichage. Cette stratégie rappelle un cycle bien connu : l’informatique personnelle a alterné entre interfaces riches et interfaces minimales. Dans les années 2000, l’iPod a démontré qu’un usage ciblé et simple peut conquérir le marché, même sans polyvalence totale. Ensuite, les smartphones ont tout absorbé, mais la saturation d’écran a relancé l’intérêt pour des objets spécialisés.
Des lunettes audio, par exemple, peuvent offrir des notifications et des échanges courts sans imposer de sortir un téléphone. En parallèle, un haut-parleur intelligent sans écran évite l’effet « tablette fixe » et privilégie l’écoute. Cependant, l’absence d’affichage oblige à une précision extrême du dialogue, car l’utilisateur ne peut pas “relire” une consigne.
Cas d’usage réalistes : maison, mobilité, travail
Dans un foyer, un appareil vocal optimisé peut orchestrer des routines, mais aussi aider à apprendre. Un enfant peut demander une explication de calcul mental, puis relancer avec « attends, refais plus lentement ». Cette nuance est difficile en texte pour un jeune public. En mobilité, l’outil peut lire des résumés, trier des messages ou guider une tâche, à condition que la latence soit faible.
Au bureau, les choses se compliquent. La voix expose le contenu aux oreilles voisines, donc la confidentialité devient un frein. Pourtant, un mode “chuchotement” ou des oreillettes dédiées peuvent contourner cet obstacle. La vraie question devient alors : l’objet est-il pensé avec des accessoires adaptés, ou se contente-t-il d’être un micro sur batterie ? Cette réponse déterminera l’adoption.
Pour mieux situer ces enjeux, une comparaison avec les approches déjà visibles sur le marché aide à clarifier ce que l’audio peut vraiment apporter.
Comparaison des technologies audio : ChatGPT face aux assistants vocaux et aux nouveaux modèles
Le marché n’attend pas OpenAI pour proposer des assistants vocaux. Pourtant, la différence se joue sur la capacité de raisonnement et la gestion du dialogue long. Les assistants classiques excellent dans les commandes courtes, comme “mets un minuteur”. En revanche, ils peinent dès que la demande exige un contexte persistant ou une explication structurée.
ChatGPT, avec des modèles plus avancés, se positionne plutôt sur la conversation multi-étapes. C’est utile pour planifier un voyage, dépanner un appareil, ou rédiger un message complexe. L’arrivée de modèles audio plus expressifs vise donc à faire coïncider deux mondes : la rapidité de la commande vocale et la profondeur du dialogue.
Latence, chevauchement de parole et qualité de compréhension
Trois critères déterminent l’expérience. D’abord, la latence : au-delà de quelques centaines de millisecondes, l’échange paraît artificiel. Ensuite, le chevauchement de parole : pouvoir interrompre l’assistant sans casser la session change la dynamique. Enfin, la compréhension sémantique : reconnaître une intention, mais aussi un changement d’avis en cours de phrase.
Prenons un scénario de dépannage informatique, fréquent en support. Une utilisatrice dit : « mon PC ne démarre plus, écran noir, mais les ventilateurs tournent… et j’ai un bip court ». Si la reconnaissance vocale rate “bip”, la piste matérielle s’effondre. À l’inverse, un bon traitement vocal conserve le détail, puis propose un diagnostic progressif : vérifier RAM, GPU, puis alimentation, avec des questions fermées pour confirmer.
Audio-only contre multimodal : arbitrages de produit
Un appareil sans écran force un design centré sur l’oral. Cela simplifie l’interface, mais cela impose des réponses courtes et actionnables. À l’opposé, une approche multimodale combine texte, image et son, ce qui réduit les ambiguïtés. Pourtant, le rapport suggère une famille de produits “tout audio”, donc l’effort se concentre sur la conversation.
Dans la pratique, un compromis est probable via le smartphone. L’objet audio gère l’échange, tandis que le téléphone affiche une synthèse si nécessaire. Ainsi, l’audio reste la porte d’entrée, mais l’écran reste une roue de secours. Cette articulation produit fera la différence entre une démo impressionnante et un usage quotidien.
Tests et critères d’évaluation : comment juger les modèles audio de ChatGPT
Pour évaluer des modèles audio de ChatGPT, il faut sortir des impressions subjectives. Une voix “agréable” ne suffit pas si la compréhension chute en environnement réel. À l’inverse, une transcription parfaite mais une prosodie robotique fatigue l’utilisateur. Une méthodologie simple permet de tester sans matériel de laboratoire.
Le fil conducteur peut s’appuyer sur une entreprise fictive, SécuRéseau, qui déploie un assistant vocal pour aider ses techniciens. Les tests se font en trois lieux : un atelier bruyant, un véhicule en mouvement et un bureau calme. À chaque fois, la même série de tâches est jouée, afin de comparer la stabilité.
Protocole de test pragmatique pour le traitement vocal
Un bon protocole mesure la qualité de compréhension, la rapidité et la résilience. D’abord, une liste de requêtes doit inclure des hésitations et des corrections. Ensuite, des interruptions doivent être provoquées volontairement. Enfin, des mots techniques doivent être mélangés à du langage courant.
- Compréhension : taux d’erreur de transcription et bonne interprétation de l’intention.
- Dialogue : capacité à reprendre après une interruption sans perdre le contexte.
- Latence : délai entre la fin de la phrase et le début de la réponse.
- Robustesse : performance en bruit, écho, et voix éloignée du micro.
- Sécurité : réactions aux données sensibles et confirmation avant action critique.
Avec ce cadre, l’évaluation devient reproductible. De plus, il devient possible de comparer plusieurs versions de modèles, ou plusieurs périphériques micro, sans confondre logiciel et matériel.
Matériel audio : micros, casques, haut-parleurs, et impact réel
Le matériel change tout, car le micro conditionne la reconnaissance vocale. Un micro-cravate réduit le bruit ambiant, tandis qu’un micro lointain amplifie l’écho. Un casque fermé améliore la perception, mais il isole socialement. À l’inverse, un haut-parleur de salon est convivial, mais il expose les données.
Dans SécuRéseau, un test montre un écart net. En véhicule, un micro directionnel réduit les erreurs sur les références produit. Par conséquent, l’assistant fournit des procédures plus fiables. Ce gain n’est pas une “option”, car une consigne erronée en maintenance peut coûter cher. Un appareil OpenAI orienté audio devra donc intégrer un choix micro ambitieux, sinon la promesse logicielle restera théorique.
Au-delà de la performance, la question suivante devient incontournable : comment protéger la vie privée lorsque la voix devient le principal canal ?
Pour visualiser les enjeux matériels et l’état du marché des lunettes connectées, un aperçu vidéo apporte un contexte utile.
Confidentialité, adoption sociale et innovation : les conditions de réussite d’un ChatGPT audio
Quand la voix devient l’interface, la confidentialité ne se limite plus au stockage des données. Elle concerne aussi l’espace autour de l’utilisateur. Une question posée à haute voix peut révéler un projet, un problème de santé ou une information financière. Ainsi, une solution audio doit prévoir des modes discrets, mais aussi des indicateurs clairs sur l’écoute et l’enregistrement.
L’adoption sociale compte autant que la performance. Par exemple, parler à un assistant dans un train reste gênant pour certains. En revanche, des oreillettes ou des lunettes à conduction osseuse rendent l’usage plus acceptable. De plus, des interactions brèves, basées sur des commandes compactes, réduisent l’exposition.
Mesures techniques attendues : local, cloud, et contrôle utilisateur
Un appareil audio moderne doit proposer des choix explicites. D’abord, un mode local pour certaines commandes simples peut limiter les envois de données. Ensuite, un mode cloud reste utile pour les requêtes complexes, car il donne accès à des modèles plus lourds. Enfin, un historique vocal doit être gérable, avec suppression rapide et règles de rétention.
Un autre point clé concerne l’authentification. Une voix peut déclencher des actions, donc il faut empêcher une activation par une personne voisine. Des mécanismes de “voice ID” existent, mais ils doivent rester robustes en bruit. À défaut, une confirmation secondaire via smartphone peut sécuriser les opérations sensibles.
Pourquoi l’innovation audio peut redéfinir l’usage de l’intelligence artificielle
Si le traitement vocal devient naturel, l’intelligence artificielle sort du cadre “outil” pour devenir un compagnon de tâche. Un artisan peut demander une procédure, puis ajuster en temps réel. Un étudiant peut explorer un sujet en marchant, sans écran. Une personne âgée peut obtenir de l’aide sans manipulations complexes. Dans chacun de ces cas, l’audio réduit la barrière d’entrée.
Cependant, l’innovation doit rester utile. Un écosystème entièrement vocal ne peut pas ignorer les moments où le texte est meilleur, comme en réunion ou en espace partagé. La stratégie gagnante reposera donc sur un audio excellent, mais aussi sur des passerelles vers le texte. « Quand la voix devient enfin fiable, l’assistant cesse d’être une application et commence à être une présence. »
Qu’est-ce que le rapport annonce exactement sur les modèles audio de ChatGPT ?
Le rapport indique qu’OpenAI préparerait une nouvelle architecture de modèles audio pour ChatGPT, avec une voix plus naturelle et une meilleure gestion des interruptions. Il mentionne aussi la capacité à dialoguer de manière plus fluide, y compris lors de chevauchements de parole, ce qui rapproche l’échange d’une conversation humaine.
Pourquoi OpenAI miserait sur un appareil largement axé audio ?
Un appareil audio libère les mains et les yeux, donc il fonctionne mieux en mobilité, en cuisine, en atelier ou en voiture. En parallèle, un produit dédié peut optimiser les micros, la latence et l’ergonomie, ce qui améliore la reconnaissance vocale et la qualité de l’expérience au quotidien.
Un appareil sans écran peut-il remplacer le texte pour la plupart des usages ?
Un usage tout audio reste difficile dans les lieux partagés et pour les informations longues ou techniques. En revanche, il devient très pertinent pour les tâches courtes, l’assistance contextuelle et les situations où l’écran gêne. Dans la pratique, un couplage avec un smartphone pour afficher une synthèse peut offrir le meilleur compromis.
Quels critères permettent de tester la qualité d’un modèle audio et du traitement vocal ?
Les critères les plus utiles sont la latence, la robustesse en environnement bruyant, la gestion des interruptions, la précision de reconnaissance vocale sur des termes techniques, et la sécurité (confirmation avant action sensible). Un protocole reproductible, répété dans plusieurs environnements, permet de comparer versions logicielles et matériels micro.




