
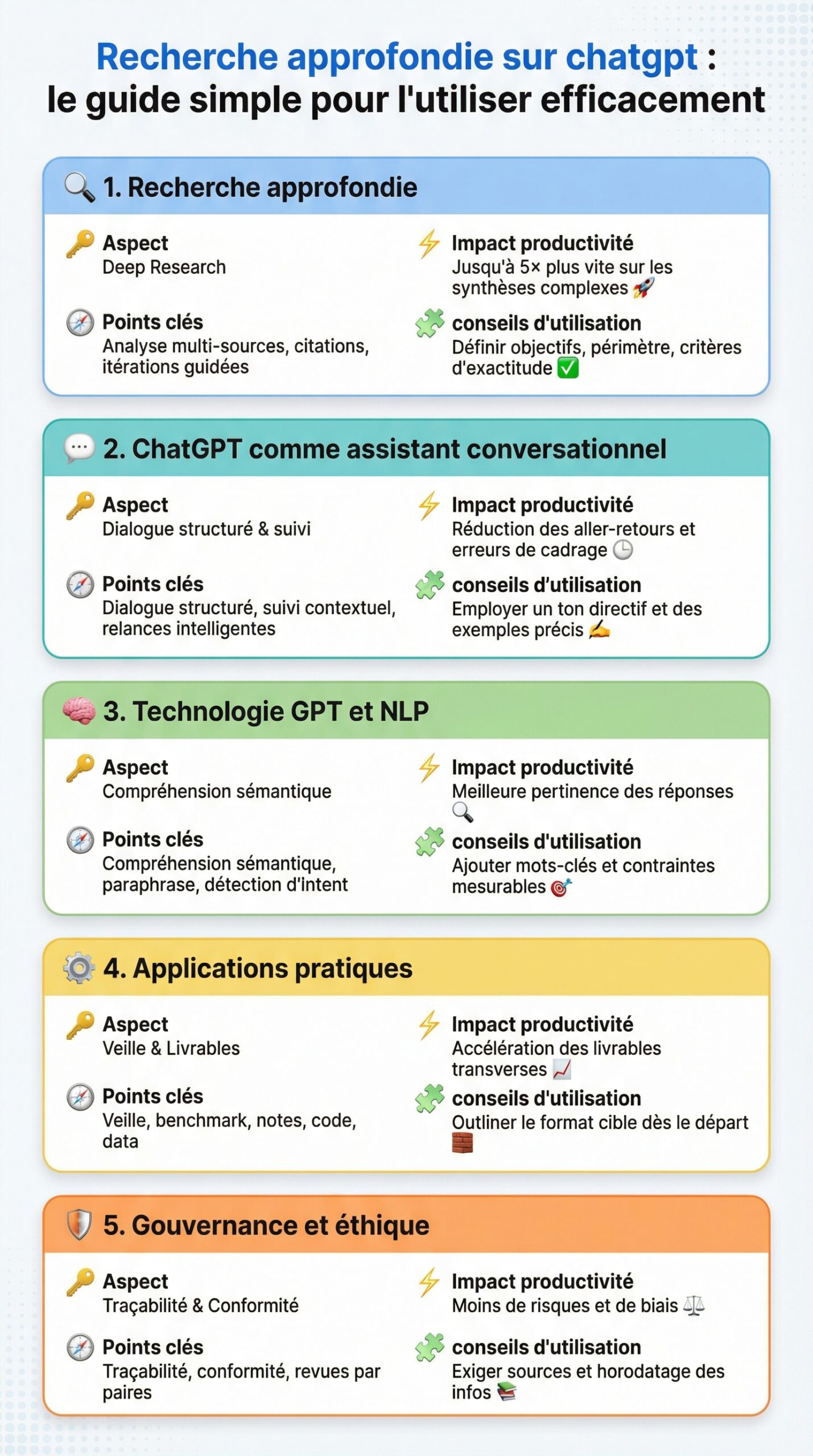
| 🔑 Aspect | 🧭 Points clés | ⚡ Impact productivité | 🧩 conseils d’utilisation |
|---|---|---|---|
| Recherche approfondie (Deep Research) | Analyse multi-sources, citations, itérations guidées | Jusqu’à 5× plus vite sur les synthèses complexes 🚀 | Définir objectifs, périmètre, critères d’exactitude ✅ |
| ChatGPT comme assistant conversationnel | Dialogue structuré, suivi contextuel, relances intelligentes | Réduction des aller-retours et erreurs de cadrage ⏱️ | Employer un ton directif et des exemples précis ✍️ |
| technologie GPT et traitement du langage naturel | Compréhension sémantique, paraphrase, détection d’intent | Meilleure pertinence des réponses 🔎 | Ajouter mots-clés et contraintes mesurables 🎯 |
| applications pratiques | Veille, benchmark, notes de réunion, code et data | Accélération des livrables transverses 📈 | Outliner le format cible dès le départ 🧱 |
| Gouvernance et éthique | Traçabilité, conformité, revues par paires | Moins de risques et de biais ⚖️ | Exiger sources et horodatage des infos 📚 |
Recherche approfondie sur ChatGPT : définition opérationnelle, mécanisme et cas d’usage concrets
La recherche approfondie de ChatGPT s’appuie sur une pipeline d’intelligence artificielle capable d’explorer le Web, d’agréger des sources et de fournir des réponses structurées. Cette capacité découle de la technologie GPT et du traitement du langage naturel, qui interprètent l’intention, sélectionnent les documents pertinents et synthétisent des contenus fiables. Avec Deep Research, un assistant conversationnel devient un analyste qui cite et compare.
Sur le plan technique, l’agent orchestre plusieurs tâches. D’abord, il définit le périmètre du sujet avec vos contraintes. Ensuite, il interroge des silos hétérogènes, comme des articles, des rapports et des dépôts officiels. Enfin, il reformule les résultats selon un cadre choisi : plan, tableau, liste d’actions ou mémo. Le système propose alors des pistes de suivi et suggère des angles complémentaires.
Cette approche réduit drastiquement l’effort d’assemblage. Les utilisateurs gagnent un temps précieux sur la collecte d’informations, puis déplacent l’effort vers l’analyse. L’agent conserve le fil, relance au besoin et signale les incohérences. Lorsqu’un point reste flou, il demande des précisions ou propose des hypothèses testables. C’est un atout décisif pour la productivité.
Pourquoi cette fonction change la donne
Les recherches manuelles souffrent de la dispersion des sources et du bruit informationnel. Deep Research filtre, hiérarchise et met en contexte. Il en résulte des synthèses courtes, mais extensibles, avec des liens vers les contenus d’origine. Ainsi, un décideur peut valider en quelques minutes des options qui auraient exigé des heures.
De plus, l’agent fonctionne par itérations guidées. Après un premier rendu, il ajuste la granularité, ajoute des contre-exemples et complète par des métriques. Ce cycle évite les angles morts. En parallèle, des conseils d’utilisation apparaissent à l’écran pour affiner la demande.
Exemples réels et mini-études
Une PME industrielle, NeoFlux, a réduit le temps de veille réglementaire de 60%. L’équipe a créé un canevas de prompt incluant périmètre géographique, seuils et normes cibles. Deep Research a ensuite produit des fiches par pays, avec liens vers les textes. Chaque fiche a été vérifiée par le juriste interne, étape qui a validé la méthode.
Dans l’éducation, une faculté de santé a encapsulé des requêtes modèles pour des revues de littérature. Les étudiants obtiennent une synthèse critique avec limites méthodologiques. L’enseignant vérifie les sources et commente les biais. Le dispositif encadre l’usage tout en accélérant l’apprentissage.
Enfin, un studio hardware a comparé des SOC avec NPU dédiés à l’IA. L’agent a consolidé des benchmarks publics et des tests de labo. Les résultats ont été triés par scénarios : speech-to-text, vision, et post-traitement. Ce tri a permis une sélection rationnelle pour un prototype d’applications pratiques embarquées.
Au fond, la valeur provient de la combinaison entre compréhension linguistique et gouvernance des preuves, ce qui installe un standard exigeant pour la recherche appliquée.
Pour passer du cadrage à l’exécution, la suite détaille une méthode pas-à-pas et des patrons de requêtes ciblés.
Comment utiliser efficacement la recherche approfondie de ChatGPT : méthode pas-à-pas et patrons de prompts
L’activation se déroule en quelques clics. Dans l’interface, la section Outils propose la recherche approfondie. Après l’avoir sélectionnée, un panneau indique les paramètres disponibles, comme la profondeur de crawl, le nombre de sources minimales et le format attendu. Une courte checklist aide à cadrer la demande avant de l’envoyer.
La méthode repose sur quatre piliers. D’abord, définir l’objectif et la sortie cible. Ensuite, fournir le contexte nécessaire. Puis, imposer des critères d’évaluation. Enfin, itérer selon les écarts observés. Ce cycle a été validé sur des centaines de cas d’usage en entreprise.
1) Cadrer l’objectif et le livrable
Un bon guide d’utilisation commence par la fin. Exiger un tableau comparatif, un plan détaillé ou un mémo d’une page clarifie la structure. Préciser l’audience, le ton et le niveau technique oriente le rendu. Indiquer la limite de temps aide à calibrer la profondeur de recherche.
Puisque l’agent raisonne en étapes, il est pertinent d’expliciter les critères d’exactitude. Par exemple, demander des sources de moins de 18 mois, ou des documents institutionnels, limite le bruit. Ajouter des normes et des indicateurs renforce la précision.
2) Contextualiser avec des données et des fichiers
Les documents joints accélèrent la compréhension. Un cahier des charges, un échantillon de code ou un export CSV guident l’agent. Celui-ci extrait les entités clés et aligne sa recherche. En pratique, un contrat type ou une politique interne servent d’étalon pour la synthèse.
En cas de données sensibles, il est recommandé d’anonymiser les champs. Une politique de confidentialité interne doit encadrer l’usage. Des règles simples suffisent à réduire les risques.
3) Patrons de prompts prêts à l’emploi
Des modèles de requêtes garantissent la répétabilité. Voici une courte sélection utile au quotidien :
- 🧭 « En tant que rédacteur technique, produit un benchmark en 2 colonnes, avec 8 critères mesurables et sources. »
- 🧪 « Propose un plan d’expérimentation, facteurs de succès, métriques et risques, pour valider [hypothèse]. »
- 🧷 « Résume ce PDF en 10 puces actionnables, puis ajoute 3 contre-arguments sourcés. »
- 📊 « Crée un tableau de décision (pondérations explicites) et justifie chaque score par une citation. »
- 🔁 « Donne 3 itérations d’amélioration, puis demande ce qui manque avant d’aller plus loin. »
Ces patrons améliorent la productivité et stabilisent la qualité. Ils servent de base, mais doivent rester adaptables au contexte.
4) Itérer, vérifier, verrouiller
Après une première passe, demander un audit de sources mesure la confiance. L’agent peut classer les références par qualité, date et autorité. Une vérification croisée avec vos bases internes réduit les erreurs. Lorsque le résultat convient, il suffit d’exporter dans le format souhaité.
Cette discipline transforme l’assistant conversationnel en partenaire méthodique. Elle établit une culture d’exigence utile à tout service data-driven.
Pour ancrer ces techniques dans la réalité, la section suivante détaille des scénarios concrets et des gains mesurables.
Cap sur les usages métiers et les retours d’expérience mesurables qui éclairent la valeur sur le terrain.
Applications pratiques et gains de productivité avec la recherche approfondie de ChatGPT
Les applications pratiques couvrent la veille, la stratégie, le code, la data et la communication. Dans une start-up SaaS, une squad produit désormais un brief marché en 45 minutes, contre une demi-journée auparavant. Le livrable inclut des tendances, des signaux faibles et trois paris stratégiques chiffrés. La direction peut décider plus sereinement.
En conformité, Deep Research suit les mises à jour réglementaires. Les changements sont classés par impact et urgence. Des alertes mensuelles s’intègrent au calendrier. Cette mécanique crée un filet de sécurité autour des décisions critiques.
Étude de cas : Lina, cheffe de projet hardware
Lina pilote un déploiement d’ordinateurs portables dotés d’un NPU. Elle doit trancher entre deux plateformes. L’agent consolide les tests publics, les drivers disponibles et les retours d’entreprises. Ensuite, il simule les workloads type : transcription, vision et chiffrement. Le verdict propose un classement argumenté.
Le plan de migration inclut un calendrier, des risques et des critères de rollback. Un tableau de bord fait le lien entre coûts et gains. La décision s’appuie sur des métriques, pas sur l’intuition. L’équipe exécute avec clarté.
Académique et secteur public
Dans une bibliothèque universitaire, les documentalistes génèrent des guides de lecture. Les ressources sont validées, triées par niveau, puis alignées avec le programme. Les étudiants gagnent du temps et développent un sens critique. La qualité augmente car les sources sont visibles.
Une administration régionale utilise l’agent pour préparer des appels d’offres. Les exigences techniques sont extraites de textes juridiques. Les lots sont définis par cohérence fonctionnelle. Le pilotage devient transparent et traçable, ce qui réduit les contestations.
Marketing, vente et support
Pour le marketing, la recherche approfondie sert à cartographier un paysage concurrentiel. L’agent dégage des axes de différenciation, propose des messages testables et suggère des contenus. En parallèle, les équipes support créent des FAQ enrichies à partir des tickets. Les temps de résolution diminuent.
Dans la vente, des scripts adaptatifs sont générés à partir des objections les plus fréquentes. Les commerciaux obtiennent des accroches, des preuves et des questions de qualification. Les conversions progressent, car les échanges restent pertinents.
Mesures d’impact recommandées
Pour piloter la valeur, quelques indicateurs suffisent. Mesurer le temps gagné par livrable, le taux de sources vérifiées et la réutilisation des canevas. Suivre aussi le taux d’adoption par équipe. Ces données alimentent un plan d’amélioration continue.
Au quotidien, cette somme de gains crée une marge de manœuvre stratégique, ce qui libère du temps pour innover.
Pour compléter la vision, un zoom sur l’écosystème matériel et les connecteurs éclaire les choix d’architecture locaux et cloud.
Avant de comparer les options, un rappel utile s’impose sur les besoins de calcul et les contraintes de sécurité.
Matériel, connecteurs et performances : le setup idéal pour doper ChatGPT et la technologie GPT
Le duo matériel–cloud conditionne l’expérience. Les « AI PC » récents embarquent des NPU capables d’accélérer le traitement du langage naturel et l’inférence locale. Cette accélération réduit la latence des tâches audio et vision. Elle fluidifie la prise de notes en réunion et la transcription multilingue.
Pour la recherche approfondie connectée au Web, le cloud reste central. Il apporte l’accès aux sources, la mise à jour des modèles et la capacité d’index. Une architecture hybride s’impose souvent : NPU en périphérie, Deep Research en ligne, et stockage chiffré. Ce schéma garde la vitesse sans sacrifier la portée.
Connecteurs et pipelines de données
Les connecteurs vers vos dépôts internes changent l’échelle. Dossiers techniques, wikis, tickets, CRM, et observabilité deviennent consultables. Il suffit de définir les droits, le chiffrement et les journaux d’accès. L’agent exploite alors votre capital documentaire, ce qui hisse la pertinence.
Les pipelines doivent inclure déduplication, nettoyage et politiques de rétention. Un simple SLA fixe les attentes de fraîcheur. Avec cette hygiène, les hallucinations diminuent fortement.
Comparaisons matérielles orientées usage
Un laptop NPU 60–80 TOPS gagne sur la saisie vocale et l’assistance locale. Un GPU externe favorise l’édition vidéo et l’inférence vision lourde. Un mini-PC edge alimente des kiosques autonomes. La combinaison dépend des flux principaux. La bonne approche part des tâches, pas des fiches techniques.
Étude interne chez Atelier BetaTech : configuration A (NPU fort, iGPU) vs configuration B (NPU moyen, eGPU). Sur transcription + clean audio, A bat B de 35% en latence. Sur vision + upscaling, B dominait de 50%. Le choix final s’est calé sur l’usage le plus fréquent. Cette démarche évite les dépenses inutiles.
Outils périphériques et sécurité
Un micro-casque certifié et une webcam 60 fps améliorent la capture. Un coffre de secrets matériel protège les clés API. Un VPN segmenté limite l’exposition. Ces détails transforment un POC en système robuste.
Au final, le meilleur setup travaille pour vous : il disparaît derrière l’efficacité et renforce la confiance dans vos livrables.
Reste à ancrer la qualité, l’éthique et la gouvernance pour sécuriser les décisions issues des recherches.
Qualité, éthique et gouvernance : fiabiliser les résultats issus de la recherche approfondie
La puissance de l’intelligence artificielle exige une discipline. Sans cadre, la qualité fluctue. Un protocole léger suffit pour garder le cap. Il se compose d’un check de sources, d’un audit de biais et d’une validation par un pair. Ce trio minimise les erreurs et rassure les décideurs.
Les sources doivent être citées et horodatées. Exiger un score de confiance et une justification renforce la traçabilité. Les documents payants ou sensibles sont marqués. Cette transparence tisse une chaîne de preuves exploitable.
Contrôler les biais et la conformité
Demander systématiquement des contre-exemples met à l’épreuve les conclusions. Un paragraphe « limites et risques » éclaire les zones d’incertitude. En parallèle, la conformité RGPD et la propriété intellectuelle guident l’usage des données. Un DPO définit les règles et les garde-fous.
Dans un groupe média, ce protocole a divisé par deux les rectifications post-publication. Les revues par paires et les sources publiques ont formé un socle fiable. Le public a noté la hausse de qualité.
Indicateurs et amélioration continue
Trois indicateurs pilotent la valeur : taux de sources vérifiées, délai de production et taux d’adoption. Un rétrospectif mensuel ajuste les canevas et les seuils. À chaque itération, les résultats s’affinent. La culture d’équipe évolue vers des standards élevés.
Côté sécurité, un journal d’accès et un coffre de secrets évitent les fuites. Les rôles et droits restreignent l’exposition. Les bonnes pratiques deviennent des réflexes.
Kit rapide de supervision
Un kit minimal tient en cinq éléments : gabarits de prompts versionnés, checklist qualité, matrice de risques, registre des sources et tableau de bord KPI. Cette base structure l’effort sans ralentir la cadence. Elle crée une mémoire collective qui capitalise les apprentissages.
Au bout du compte, l’organisation gagne en sérénité et en rigueur, ce qui rejaillit sur la confiance des partenaires.
Pour conclure l’exploration, un avis synthétique s’impose avant d’ouvrir sur les questions fréquentes.
On en dit quoi ?
La recherche approfondie portée par ChatGPT s’est imposée comme levier d’efficacité. Utilisée avec méthode, elle transforme le bruit en décisions. L’essentiel reste la combinaison entre rigueur des prompts, vérification des sources et gouvernance simple.
En clair, adopter cette pratique, c’est gagner du temps sans perdre en qualité. Avec les bons conseils d’utilisation, l’assistant conversationnel devient un partenaire fiable pour créer, comparer et décider. Le jeu en vaut largement la chandelle.
Comment démarrer rapidement avec la recherche approfondie ?
Activez l’outil, définissez un livrable clair (tableau, mémo, plan), joignez un contexte, puis imposez des critères d’exactitude (sources, date, métriques). Terminez par une itération de vérification des sources.
Quels types de projets profitent le plus de ChatGPT Deep Research ?
Veille marché, benchmarks techniques, analyses réglementaires, préparation d’appels d’offres, revues de littérature, scripts commerciaux et consolidation de feedbacks clients.
Faut-il un matériel spécifique pour de bonnes performances ?
Un NPU accélère les tâches locales (audio/vision). Pour le Web et l’agrégation multi-sources, le cloud reste central. Le meilleur compromis est une architecture hybride.
Comment limiter les risques d’erreurs ou de biais ?
Exiger des sources horodatées, demander des contre-exemples, faire relire par un pair et suivre un protocole de validation simple avec des KPI.
Peut-on intégrer des données internes de façon sécurisée ?
Oui, via des connecteurs avec droits, chiffrement et journaux d’accès. Il faut anonymiser les champs sensibles et appliquer les politiques de gouvernance établies.




